Many years ago in a relational database world, increasing the scalability and performance of a software system was fairly simple
- Modify your application/SQL to run more efficiently – Performance tuning.
- Increase your hardware resources. Scaling up means bigger machines, more processors, disk storage and memory. This gets expensive and there are some real limits on how high we can go.
But with ever increasing internet-scale data and the applications’ need for fast querying and fast analytics, the relational databases have quickly hit their upper limit. In such cases it is no longer acceptable to run a single server with a single database. The alternative is to use lots of small machines in a cluster. This is the basis for the NoSQL movement.
There are many advantages of running a NoSQL database in a cluster.
- It’s cheaper, since we can use commodity hardware.
- It’s more resilient, even if individual machines fail, the cluster can keep going providing high reliability.
- They are mostly open-source. So no need for expensive licenses with big corporations.
- They are schema-Less which enables rapid development and more flexibility.
However, like any other solution it comes with some trade-offs. Eric Brewer defines these trade-offs in what is called CAP Theorem.
Every distributed system has 3 main attributes :-
Consistency (C) – All nodes in the cluster see the same data at the same time
Availability (A) – Every request to the cluster gets a response, even if individual nodes in the cluster are broken
Partition Tolerance (P) – The cluster continues to work despite any network failure that divides the cluster into multiple partitions.
What exactly is Partition Tolerance ?
Look at the diagram below
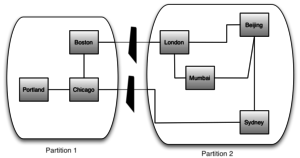
We have many nodes that store data distributed across the world. Literally speaking these nodes are computers connected using networks. Any communication breakages in networks can and do happen. In this example, by just having two failures in the network, our cluster gets divided into two partitions unable to communicate with each other. Partition Tolerance is defined as the ability of a cluster to continue functioning even when there is network partition.
CAP Theorem
It states In a distributed system, given the three options of consistency, availability and partition tolerance, we can only guarantee two of them.
Lets look at it with an example.
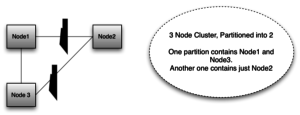
The first partition contains Node1 and Node3 and the second one contains Node2.
In this scenario, Node2 is not receiving any updates written to Node1 and Node3. Similarly Node1 and Node3 are not receiving any updates written to Node2. In such a case we have two options.
- Keep Node2 Alive – This will make sure all nodes are available, but they will not be consistent. The nodes are available and partition tolerant but not consistent. We are sacrificing consistency for achieving more availability.
- Kill Node2 – If we shutdown node2, there will be only 2 nodes (node1 and node3) which are both consistent. In this case we have sacrificed some availability to achieve consistency.
Practically speaking what CAP theorem states is that, In a system that may suffer partitions, you have to trade-off consistency vs availability. Also this isn’t a binary decision, as seen in the Kill Node2 example above. We can sacrifice a little availability for consistency.